



I. Introduction▲
Ce tutoriel va s'intéresser à Spark, framework de manipulation de données en mémoire dans un écosystème BigDATA, écosystème que j'ai essayé de vaguement vous modéliser avec l'image suivante :

Pour cet article, on va se concentrer sur la partie manipulation des données avec Spark, donnée qui est stockée sous forme de fichiers CSV sur un système de fichier Hadoop. Ces fichiers sont issus du site open data de la SNCF.
II. Prérequis▲
Le fichier CSV qui recense les validations des titres de transport des voyageurs SNCF en Île-de-France, par gare, par jour, pour le premier semestre 2015 à télécharger ici. Ce ficher pèse 43 Mo et contient 755 990 lignes. L'image suivante représente l'entête du fichier + quelques lignes :

III. Architecture▲
III-A. Hadoop 2.7.2▲
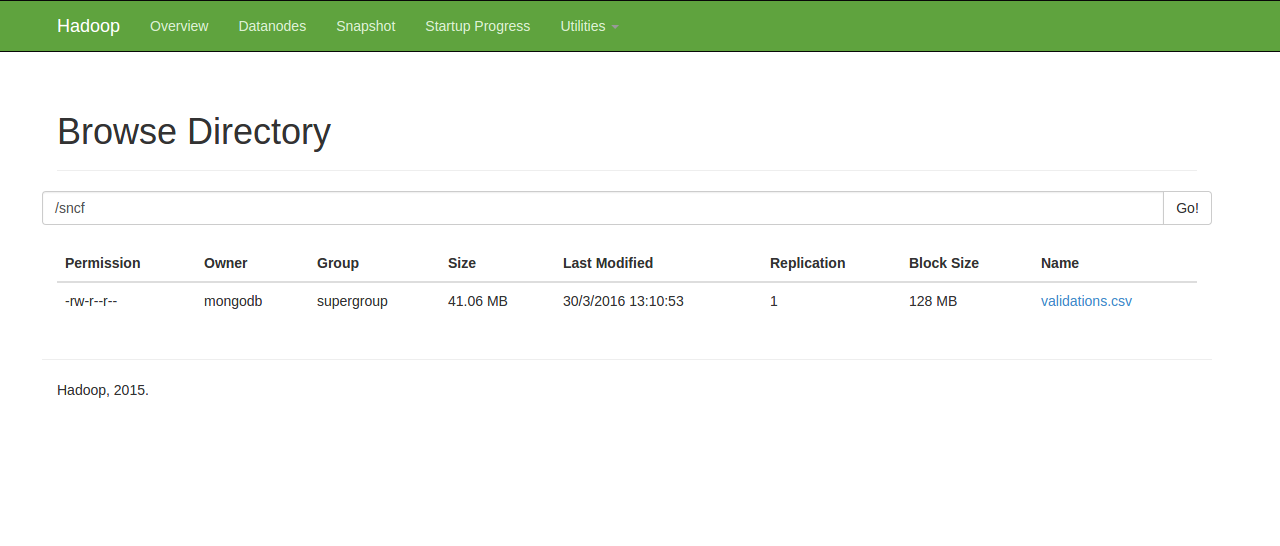
Pour notre cas, j'ai installé Hadoop et j'y ai stocké notre fichier de données. Le fichier se nomme validations.csv et est accessible sur via l'URI hdfs://10.46.245.149/sncf/validations.csv où la machine 10.46.245.149 est une machine dédiée pour Hadoop.
III-B. Spark 1.6.0▲
Nous utiliserons l'API Java Spark-Core qui permet des manipulations de base sur les données. Si vous utilisez Maven, vous pouvez l'inclure comme ceci :
2.
3.
4.
5.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.6.0</version>
</dependency>
IV. API Spark Core▲
Une fois tout correctement installé, on peut commencer à manipuler les données du fichier validations.csv avec Spark ! L'idée, c'est de configurer Spark pour aller lire ce fichier depuis Hadoop et ensuite faire des requêtes sur les données comme : « Le nombre total de voyageurs qui ont validé leur titre de transport sur le semestre 1 de 2015 ? », « Moyenne de validation par mois sur le semestre ? », etc.
IV-A. Configuration▲
Pour utiliser l'API Spark, il faut commencer par créer une configuration Spark Java :
2.
3.
4.
SparkConf conf = new SparkConf();
conf.setAppName("Spark Hadoop");
conf.setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(conf);
Cette configuration précise à Spark que notre application se nomme "Spark Hadoop" et que l'on souhaite que Spark s'exécute sur la machine locale.
IV-B. Récupération des données▲
Une fois la conf Spark initialisée, il faut aller chercher le fichier **validations.csv** sur Hadoop et le charger en mémoire, rien de plus facile vu que Spark s'intègre facilement avec le Hadoop File System.
JavaRDD<String> lines = sparkContext.textFile("hdfs://10.46.245.149/sncf/validations.csv");
Ceci nous permet de récupérer le contenu du fichier dans un RDD (Resilient Distributed Datasets) qui sont des structures de données qui se veulent tolérantes aux pannes mémoire et utilisables en parallèle. On peut confirmer la récupération du fichier en comptant le nombre de lignes de ce dernier.
2.
long count = lines.count();
System.out.println(count);
Le résultat attendu sera le suivant :
> 755990
V. Manipulations▲
V-A. Mapping▲
Maintenant que nous avons récupéré le contenu de notre fichier validation.csv dans un RDD de chaînes de caractères, il serait plus intéressant de transformer chaque ligne en objet Validation.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
public class Validation implements Serializable
public LocalDate jour;
public String codeStifTrns;
public String codeStifRes;
public String codeStifArret;
public String libelleArret;
public String idRefaLda;
public String titre;
public Long validations;
public Validation(String validation) {
String split[] = validation.split(";");
this.jour = LocalDate.parse(split[0]);
this.codeStifTrns = split[1];
this.codeStifRes = split[2];
this.codeStifArret = split[3];
this.libelleArret = split[4];
this.idRefaLda = split[5];
this.titre = split[6];
this.validations = split.length == 8 ? Long.valueOf(split[7]) : 0;
}
// Getters et Setters ...
Rien de plus facile :
2.
3.
4.
5.
6.
7.
JavaRDD<Validation> validations = lines
// On filtre le Header du CSV
.filter(line -> !line.equals("JOUR;CODE_STIF_TRNS;CODE_STIF_RES;CODE_STIF_ARRET;LIBELLE_ARRET;ID_REFA_LDA;CATEGORIE_TITRE;NB_VALD"))
// On transforme chaque ligne en Objet Validation
.map(Validationnew);
// On met le RDD en cache mémoire pour une prochaine utilisation
validations.cache();
V-B. Requêtes▲
Nous allons maintenant jouer avec nos données de validation en faisant des requêtes sur celles-ci.
Requête 1 : nombre total de voyageurs qui ont validé leur titre de transport dans le réseau ferré en Île-de-France sur le 1er semestre 2015 ?
long totalValidations = validations.map(ValidationgetValidations).reduce((v1, v2) -> v1 + v2);
Le résultat attendu sera le suivant
> 752 690 612
Requête 2 : nombre total de voyageurs qui ont validé leur titre de transport dans le réseau ferré en Île-de-France sur le mois de janvier 2015 ?
long totalValidationsJanvier = validations.filter(v1 -> v1.getJour().getMonth().equals(Month.JANUARY)).map(ValidationgetValidations).reduce((v1, v2) -> v1 + v2);
Le résultat attendu sera le suivant
> 128 507 177
Requête 3 : pourcentage des validations par mois ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
// On regroupe par mois
validations.groupBy(v -> v.getJour().getMonth())
// On calcule le total des validations par mois
.map(tuple -> {
Map<Month, Long> result = new HashMap<>();
result.put(tuple._1(), 0L);
tuple._2().forEach(validation -> {
result.put(tuple._1(), result.get(tuple._1()) + validation.getValidations());
});
return result;
})
// On récupère les résultats dans une map "Mois/Total validations du mois"
.reduce((v1, v2) -> {
Map<Month, Long> result = new HashMap<Month, Long>();
result.putAll(v1);
result.putAll(v2);
return result;
})
// Pour chaque ligne on divise par le total des validations du semestre et on affiche le résultat
.forEach((month, aLong) -> System.out.println(month + " : " + ( (double) aLong / totalValidations) * 100));
Le résultat attendu sera le suivant
2.
3.
4.
5.
6.
> JANUARY : 17.073041027911746 %
> MAY : 15.64424773242688 %
> JUNE : 17.679142250282247 %
> MARCH : 17.1697009288592 %
> APRIL : 16.746530910631314 %
> FEBRUARY : 15.68733714988862 %
Requête 4 : top 5 des validations par gare ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
// Comparator sur les validations par gare
static class MyTupleComparator implements Comparator<Tuple2<String, Long>>, Serializable {
final static MyTupleComparator INSTANCE = new MyTupleComparator();
public int compare(Tuple2<String, Long> t1, Tuple2<String, Long> t2) {
return t1._2.compareTo(t2._2); // sort descending
}
}
// On groupe par gare
validations.groupBy(v -> v.getLibelleArret())
// Pour chaque gare on calcule le total des validations
.mapToPair(tuple -> {
Map<String, Long> result = new HashMap<>();
result.put(tuple._1(), 0L);
tuple._2().forEach(validation -> {
result.put(tuple._1(), result.get(tuple._1()) + validation.getValidations());
});
return new Tuple2<String, Long>(tuple._1(), result.get(tuple._1()));
})
// On trie par ordre ascendant sur les validations et on garde le top 5
.top(5, MyTupleComparator.INSTANCE)
// On affiche
.stream().forEach(stringLongTuple2 -> System.out.println(stringLongTuple2._1() + " : " + stringLongTuple2._2() + " =====> " + ((double) stringLongTuple2._2() / totalValidations) * 100 + " %"));
Le résultat attendu sera le suivant
2.
3.
4.
5.
> LA DEFENSE-GRANDE ARCHE : 22488307 =====\> 2.9877225305422037 %
> SAINT-LAZARE : 15249650 =====\> 2.0260183609145375 %
> GARE DE LYON : 13768817 =====\> 1.8292797572450659 %
> MONTPARNASSE : 13477935 =====\> 1.7906341310923644 %
> GARE DU NORD : 12174125 =====\> 1.617414221183351 %
VI. Conclusion▲
On a vu dans cette première partie, à travers ces données SNCF, les opérations de base possibles avec le Spark Core Java. Nous verrons dans la prochaine partie comment faire du machine learning avec l'API Spark MLlib !
VII. Remerciements▲
Cet article a été publié avec l'aimable autorisation de Sfeir.
Nous tenons à remercier Claude Leloup pour la relecture orthographique de cet article et Mickael Baron pour la mise au gabarit.